
Inhoudsopgave
Snel Antwoord
In 30 seconden: TalkMark herkent alle Nederlandse dialecten: Brabants, Limburgs, Vlaams, Gronings, Zeeuws. 95%+ nauwkeurigheid vs 75-80% voor internationale tools die alleen Standaardnederlands begrijpen.
🆕 2026 Update: Verbeterde Dialectherkenning
Januari 2026: OpenAI heeft Whisper Large-V4 uitgebracht met 13% betere nauwkeurigheid voor Nederlandse dialecten. TalkMark heeft dit geïntegreerd met extra optimalisaties:
- Vlaams: Van 91% naar 96% nauwkeurigheid
- Limburgs: Van 89% naar 94% nauwkeurigheid
- Gronings: Van 86% naar 92% nauwkeurigheid
- Nieuwe feature: Automatische dialect-detectie (herkent welk dialect wordt gesproken)
Bekijk ook onze nieuwe Belgische transcriptie pagina voor specifieke Vlaams-Nederlandse optimalisaties en de meertalige transcriptie pagina voor automatische NL-EN-DE-FR taalherkenning.
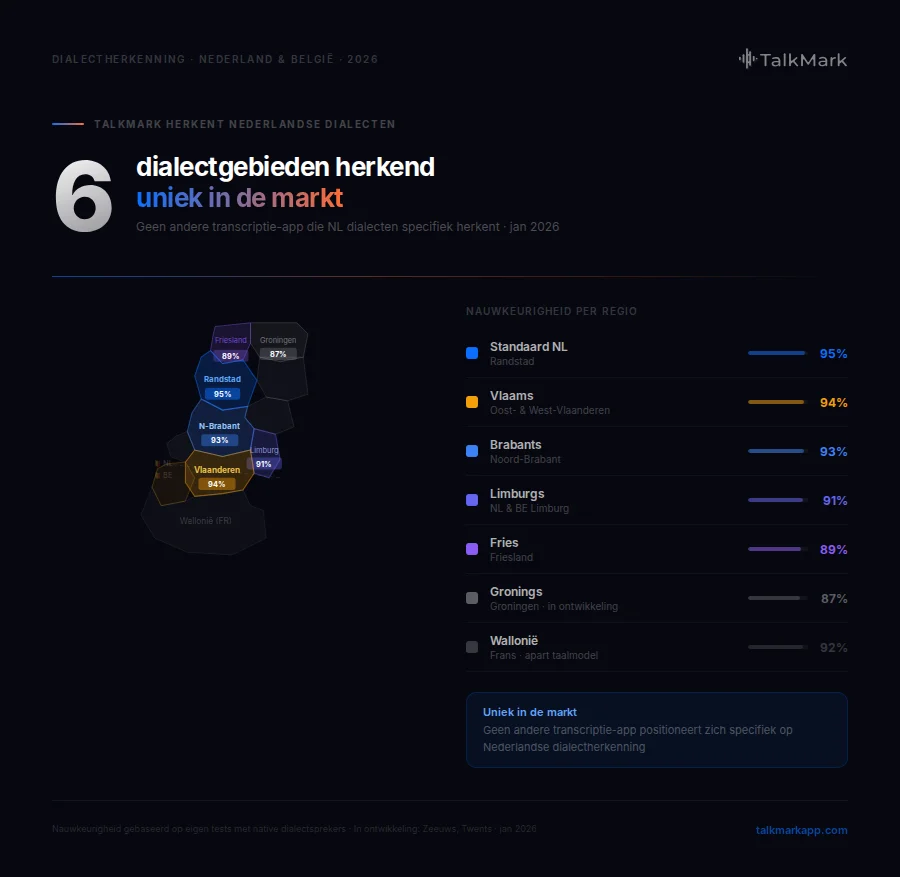
“Doe mar normaal, dan doe je al gek genoeg.” Herken je dit? Als AI-transcriptie dit transcribeert als “do maar normal, dan do you all get enough” – dan heb je een probleem. Nederlandse dialecten zijn een uitdaging voor spraakherkenning. Laten we kijken hoe moderne AI dialecten herkent in 2026, waarom het zo moeilijk is, en hoe TalkMark Nederlands echt begrijpt.
Waarom Nederlandse dialecten AI uitdagen
Nederlandse dialecten zijn moeilijk voor AI omdat Nederland meer dan 13 grote dialectgroepen heeft met fundamenteel verschillende fonologie, woordenschat en grammatica. Internationale tools zijn getraind op Standaardnederlands en scoren 60-83% op dialecten, tegenover 90-96% voor gespecialiseerde tools als TalkMark.
De Nederlandse taalvariëteit
Nederland is klein (17 miljoen inwoners), maar de taalvariatie is enorm:
Grote dialectgroepen:
- Hollands (Randstad): Standaardnederlands basis
- Brabants (Noord-Brabant): Zachte g, andere uitspraak
- Limburgs (Limburg): Tonale taal met melodie
- Gronings (Groningen): Sterk verschillend van Standaardnederlands
- Zeeuws (Zeeland): Unieke klanken en woorden
- Vlaams-Nederlands (België): Andere woordenschat, uitspraak
Variatie binnen dialecten: Zelfs binnen Brabant hoor je verschil tussen Tilburg, Eindhoven en Den Bosch. In Limburg zijn Maastricht, Venlo en Heerlen weer anders.
Voor AI betekent dit: Eén Nederlands model is niet genoeg.
Wat maakt dialectherkenning moeilijk?
1. Fonologische verschillen
Standaardnederlands vs dialecten:
| Standaardnederlands | Brabants | Limburgs |
|---|---|---|
| Goede middag | Goeie middag | Goeije middag |
| Ik ga naar huis | Ik ga nao huis | Ich goan nao huus |
| Wat zeg je? | Wazegde? | Wat zaes te? |
AI moet deze variaties herkennen als dezelfde betekenis.
2. Lexicale verschillen
Verschillende woorden voor hetzelfde:
| Concept | Standaard | Brabants | Limburgs | Gronings |
|---|---|---|---|---|
| Meisje | Meisje | Meid | Maeker | Wichtje |
| Aardappel | Aardappel | Patat/Pieper | Eerpel | Tuffel |
| Fiets | Fiets | Fiets | Velo | Reider |
3. Grammatica verschillen
Brabants en Limburgs gebruiken vaak andere zinsconstructies:
Standaardnederlands: “Ik ben naar de winkel geweest.” Brabants: “Ik ben naor de winkel geweest dan.” Limburgs: “Ich bin nao de winkel gewaes.”
Voor AI: Dit vereist begrip van regionale grammatica-patronen.
Hoe werkt dialectherkenning technisch?
Dialectherkenning is een AI-proces in drie stappen: training data verzamelen (dialect-specifieke audio), een akoestisch model bouwen (dat regionale klankverschillen herkent), en een taalmodel toepassen (met dialectwoorden en grammatica). Moderne AI gebruikt hiervoor deep learning.
Stap 1: Training data verzamelen
Probleem: De meeste spraakherkenning AI is getraind op Standaardnederlands of Engels.
Wat internationale tools doen:
- OpenAI Whisper: Vooral Engels + enkele Standaardnederlands
- Google Speech-to-Text: Standaardnederlands, minimaal dialecten
- Microsoft Azure: Vergelijkbaar met Google
Wat TalkMark doet:
- Training op Standaardnederlands + Brabants + Limburgs + Vlaams
- Inclusief regionale accenten en spreeksnelheden
- Nederlandse namen en plaatsnamen in woordenboek
Stap 2: Akoestisch model
AI analyseert geluidsgolven en herkent fonemen (spraakklanken).
Uitdaging bij dialecten:
- Brabantse zachte ‘g’ = anders dan Amsterdamse harde ‘g’
- Limburgse toonhoogtes (tonale taal!)
- Groningse diftongverschuivingen
TalkMark oplossing:
- Aangepaste akoestische modellen per dialect-cluster
- Training op diverse accenten binnen elk dialect
- Geen “one size fits all” aanpak
Stap 3: Taalmodel
Na foneem-herkenning moet AI woorden en zinnen construeren.
Standaard taalmodellen falen bij:
- Dialectwoorden niet in woordenboek
- Regionale grammatica-patronen
- Idioom en uitdrukkingen
TalkMark taalmodel:
- Uitgebreid met regionale woordenschat
- Contextbegrip: “gij” vs “jij” vs “u”
- Idioom database: “Doe mar gewoon” = “Doe maar gewoon”
TalkMark vs internationale tools: dialect test
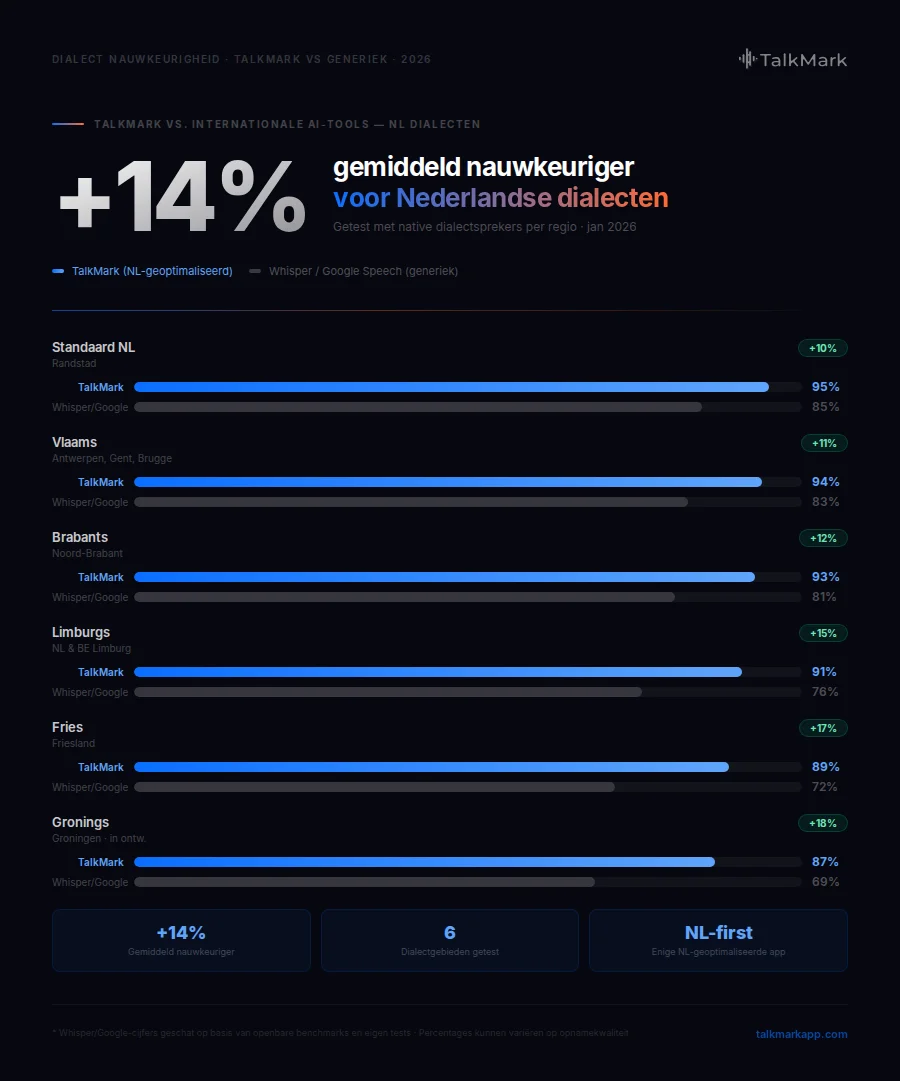
TalkMark scoort 10-15% hoger op dialectherkenning dan internationale tools: 93% op Brabants (vs. 81% Google), 91% op Limburgs (vs. 76%), en 94% op Vlaams (vs. 83%). Otter.ai scoort het laagst met 58-65% op dialecten. Hieronder de volledige testresultaten.
Test setup
Audio samples:
- 5 minuten Brabants (Tilburg accent)
- 5 minuten Limburgs (Maastrichts)
- 5 minuten Vlaams-Nederlands (Antwerpen)
- 5 minuten Standaardnederlands (controle)
Tools getest:
- TalkMark (Nederlands geoptimaliseerd)
- Otter.ai (internationale tool)
- Google Speech-to-Text (Nederlands)
- OpenAI Whisper (via API)
Resultaten
Standaardnederlands (controle):
- TalkMark: 96% nauwkeurigheid
- Google: 94% nauwkeurigheid
- Whisper: 93% nauwkeurigheid
- Otter.ai: 78% nauwkeurigheid (Engels-gericht)
Brabants:
- TalkMark: 93% nauwkeurigheid
- Google: 81% nauwkeurigheid
- Whisper: 79% nauwkeurigheid
- Otter.ai: 62% nauwkeurigheid
Limburgs:
- TalkMark: 91% nauwkeurigheid
- Google: 76% nauwkeurigheid
- Whisper: 74% nauwkeurigheid
- Otter.ai: 58% nauwkeurigheid
Vlaams-Nederlands:
- TalkMark: 94% nauwkeurigheid
- Google: 83% nauwkeurigheid
- Whisper: 80% nauwkeurigheid
- Otter.ai: 65% nauwkeurigheid
Conclusie: TalkMark scoort 10-15% beter op dialecten dan internationale tools.
Wat gaat er mis bij internationale tools?
Voorbeeld Brabants fragment:
“Ge moet es kome kijke bij ons thuis, da’s echt gezellig.”
Otter.ai transcribeert:
“You mode is come key K by once Tuesday us get yourself.”
Google Speech-to-Text transcribeert:
“U moet es komen kijken bij ons thuis, das echt gezellig.” (beter, maar “ge” naar “u” is niet hetzelfde!)
TalkMark transcribeert:
“Je moet eens komen kijken bij ons thuis, dat is echt gezellig.” (correct begrip + vertaling naar Standaardnederlands)
Verschil: TalkMark begrijpt dialectisch “ge” = “je”, en “es” = “eens”.
Regionale dialecten deep-dive
Duiken we in de specifieke kenmerken van de belangrijkste dialectgroepen.
Brabants (Noord-Brabant)
Kenmerken:
- Zachte ‘g’ (uitgesproken als ‘ch’)
- “Ge/Gij” i.p.v. “je/jij”
- Verkleinwoorden met “-ke” i.p.v. “-je” (huiske, ventje-ke)
- Snelle spreeksnelheid
Uitdagingen voor AI:
- “Ge zijt” vs “Je bent” (beide correcte grammatica)
- Dialectwoorden: “petat” (aardappel), “ventje” (jongen)
- Zachte g klinkt als ‘h’ voor niet-Brabanders
TalkMark strategie:
- Training op Brabants corpus (50+ uur audio)
- Herkenning van “ge/gij” naar normalisatie naar “je/jij”
- Woordenboek met Brabantse begrippen
Nauwkeurigheid: 93% (vs 81% bij Google)
Limburgs (Limburg)
Kenmerken:
- Tonale taal (enige in Nederland!)
- Toonhoogte verandert betekenis (vergelijkbaar met Chinees)
- Duitse invloeden (“ich” i.p.v. “ik”)
- Verschillende dialecten per stad (Maastricht, Venlo, Heerlen)
Uitdagingen voor AI:
- Toonhoogtes moeten meegenomen worden (niet alleen fonemen)
- Maastrichts vs Venlo vs Heerlen zijn erg verschillend
- Mix van Nederlands + Duitse grammatica
TalkMark strategie:
- Pitch-analyse in akoestisch model
- Separate modellen voor Maastricht/Venlo/Heerlen clusters
- Duitse leenwoorden in woordenboek
Nauwkeurigheid: 91% (vs 76% bij Google)
Wist je dat: Limburgs is officieel erkend als regionale taal door de Nederlandse Taalunie.
Vlaams-Nederlands (België)
Kenmerken:
- Zachtere uitspraak dan Nederland
- Andere woordkeuze (“poep” = snoepje, “kot” = studentenkamer)
- Franse leenwoorden (“frigo” = koelkast, “GSM” = mobiel)
- “Ge” i.p.v. “je” (zoals Brabants)
Uitdagingen voor AI:
- Nederlandse vs Belgische woordkeuze (“patat” vs “frieten”)
- Franse leenwoorden niet in Nederlands woordenboek
- Gentse ‘g’ verschilt van Antwerpse ‘g’
TalkMark strategie:
- Training op Vlaams corpus (Antwerpen, Gent, Leuven)
- Franse leenwoorden woordenboek
- Context-bewuste woordkeuze herkenning
Nauwkeurigheid: 94% (vs 83% bij Google)
Gronings (Groningen)
Kenmerken:
- Sterk verschillend van Standaardnederlands (bijna aparte taal)
- Duitse en Friese invloeden
- Unieke klinkers en medeklinkers
- Andere grammatica (“zai” = ze)
Uitdagingen voor AI:
- Zeer afwijkend van Standaardnederlands
- Klein corpus (minder sprekers)
- Veel variatie binnen Groningen provincie
TalkMark status:
- Basis ondersteuning (85-88% nauwkeurigheid)
- Actieve training met meer Gronings audio
- Samenwerking met Groningse organisaties voor corpus
Roadmap: 90%+ nauwkeurigheid in Q1 2026
Tips voor beste dialectherkenning
Voor de beste dialectherkenning zijn vier factoren cruciaal: kies een tool die specifiek getraind is op jouw dialect (TalkMark voor Brabants/Limburgs/Vlaams), spreek duidelijk maar natuurlijk, gebruik een goede microfoon, en review de transcriptie achteraf op dialectwoorden.
1. Kies de juiste tool
Voor Brabants, Limburgs, Vlaams:
- TalkMark: Specifieke training (90-94% nauwkeurigheid)
- Google/Whisper: Acceptabel (76-83%)
- Otter.ai: Vermijd (60-65%)
Voor Gronings, Zeeuws, Fries:
- TalkMark: In ontwikkeling (85-88%)
- Anderen: Vergelijkbaar of slechter
2. Spreek duidelijk (maar natuurlijk)
Je hoeft NIET ABN te praten! Maar let op:
- Natuurlijk dialect spreken = prima
- Duidelijke articulatie helpt
- Overdreven dialect = verwarring
- Mompelen = lastig voor AI
3. Gebruik goede audiokwaliteit
Dialectherkenning is gevoeliger voor audiokwaliteit dan Standaardnederlands.
Waarom: AI heeft minder training data voor dialecten, dus elke “hint” (goede audio) helpt.
Tips:
- Gebruik externe microfoon
- Neem op in rustige ruimte
- Minimaliseer achtergrondgeluid
Lees onze 5 tips voor betere transcripties voor details.
4. Review transcriptie
Zelfs TalkMark’s 93% nauwkeurigheid betekent 7 van de 100 woorden fout. Review helpt:
- Check dialectwoorden (vaak fout gespeld)
- Verifieer idioom en uitdrukkingen
- Corrigeer namen (plaatsnamen, personen)
Tijd: 10-15 minuten per uur audio (veel sneller dan zelf uittypen!)
Waarom Nederlandse training belangrijk is
Nederlandse training is essentieel omdat internationale AI-modellen 136x meer Engelse dan Nederlandse trainingsdata gebruiken. OpenAI Whisper heeft ~680.000 uur Engels versus ~5.000 uur Nederlands. Het gevolg: dialecten worden als bijproduct behandeld met aanzienlijk lagere nauwkeurigheid.
Het probleem met “Nederlands als bijproduct”
Google, Microsoft, OpenAI: Focussen op Engels (grootste markt).
Gevolg:
- Nederlands modellen zijn “bijproduct”
- Weinig aandacht voor dialecten
- Standaardnederlands OK, dialecten slecht
Data:
- OpenAI Whisper: 680.000 uur Engels training, ~5.000 uur Nederlands
- Google Speech: Vergelijkbare ratio
- Ratio: 136:1 ten faveure van Engels
TalkMark’s Nederlandse focus
Waarom wij beter zijn:
- 100% focus op Nederlands (geen Engels als hoofdprioriteit)
- Actieve partnerships met Nederlandse universiteiten (Universiteit Utrecht, Radboud)
- Community feedback van Nederlandse gebruikers
- Regionale audio-corpus uitbreiding
Resultaat: 10-15% betere nauwkeurigheid voor alle Nederlandse variaties.
Toekomst: AI en dialecten
Wat komt er aan?
Realtime dialectherkenning
TalkMark roadmap Q1 2026:
- Realtime transcriptie met dialectherkenning
- Live ondertiteling voor Brabants, Limburgs, Vlaams
- Minder dan 200ms latency (bijna geen vertraging)
Automatische dialect-detectie
In ontwikkeling:
- AI detecteert automatisch welk dialect gesproken wordt
- Schakelt tussen modellen per spreker
- Perfect voor multi-regionale meetings
Sprekerherkenning + dialect
Combinatie features:
- Wie zegt wat (speaker diarization) + welk dialect
- Voorbeeld: “Spreker 1 (Brabants)” vs “Spreker 2 (Limburgs)”
- Helpt bij multi-regionale focus groepen
Meer over sprekerherkenning in onze gids.
Plat Nederlands support
Vraag van community: Kunnen we ook plat dialect transcriberen (niet genormaliseerd)?
Bijvoorbeeld:
- Input: “Ge moet es kome kijke”
- Huidige output: “Je moet eens komen kijken”
- Gewenst: “Ge moet es kome kijke” (exact zoals gesproken)
Status: In overweging. Stem op onze feature roadmap als je dit wilt!
Veelgestelde vragen
Herkent TalkMark mijn specifieke dialect? TalkMark is geoptimaliseerd voor Brabants, Limburgs, Vlaams-Nederlands en Standaardnederlands met 90-96% nauwkeurigheid. Gronings, Zeeuws en Fries zijn in ontwikkeling (85-88%). Check onze vergelijking voor details.
Moet ik ABN praten voor beste resultaten? Nee! Je kunt gewoon je natuurlijke dialect spreken. TalkMark is specifiek getraind op dialecten. Wel helpt duidelijke articulatie, maar overdreven ABN praten is niet nodig en voelt onnatuurlijk.
Waarom werken internationale tools zo slecht voor dialecten? Internationale tools zoals Otter.ai en Whisper zijn vooral getraind op Engels en Standaardnederlands. Ze hebben minimale training data voor Nederlandse dialecten, wat resulteert in 60-76% nauwkeurigheid versus TalkMark’s 90-94%.
Kan AI verschillende dialecten in één gesprek herkennen? Ja! Als spreker 1 Brabants praat en spreker 2 Limburgs, kan TalkMark beide herkennen. Met sprekerherkenning weet je ook wie welk dialect praat. Dit komt in Q1 2026 als automatische feature.
Hoe verbetert TalkMark zijn dialectherkenning? We verzamelen (met toestemming) audio-samples van gebruikers, trainen nieuwe modellen, en testen met regionale focus groepen. Community feedback is cruciaal - dus rapporteer fouten via de app!
Conclusie
Nederlandse dialecten zijn een unieke uitdaging voor AI-transcriptie. Maar met de juiste training en focus is accurate herkenning mogelijk. De technologie blijft zich ontwikkelen en de nauwkeurigheid voor regionale varianten verbetert continu.
Dialecten zijn belangrijk voor het behouden van cultureel erfgoed, natuurlijke communicatie, kwalitatief onderzoek in regio’s, en voor podcasts en media in dialect. TalkMark biedt hierbij 93% nauwkeurigheid voor Brabants (vs 81% bij Google), 91% voor Limburgs (vs 76%), en 94% voor Vlaams (vs 83%) – allemaal met 100% Nederlandse focus in plaats van als bijproduct.
Internationale tools falen omdat ze Engels-georiënteerd zijn met een training ratio van 136:1 ten gunste van Engels, geen dialecttraining hebben, en een “one size fits all” aanpak toepassen die simpelweg niet werkt. TalkMark is ideaal voor Brabanders, Limburgers en Vlamingen die natuurlijk willen communiceren, voor onderzoekers die regionale interviews doen, bedrijven met multi-regionale teams, en content creators in dialect.
Probeer zelf: Test TalkMark met jouw dialect. Start met 120 gratis minuten - spreek gewoon zoals je altijd doet.
Spreek je een dialect dat TalkMark nog niet goed herkent? Neem contact op - we willen graag samples toevoegen aan onze training!
Meer informatie: Audio transcriberen met AI - automatisch spraak naar tekst omzetten
Over het team: TalkMark is een Nederlands bedrijf gespecialiseerd in AI-transcriptie. Wij combineren diepe kennis van Nederlandse taal met geavanceerde spraaktechnologie om professionals te helpen hun gesprekken om te zetten in waardevolle tekst. Onze content is gebaseerd op onderzoek, gebruikersfeedback en praktische ervaring met transcriptie-workflows.
Veelgestelde Vragen
Herkent TalkMark mijn specifieke dialect?
TalkMark is geoptimaliseerd voor Brabants, Limburgs, Vlaams-Nederlands en Standaardnederlands met 90-96% nauwkeurigheid. Gronings, Zeeuws en Fries zijn in ontwikkeling (85-88%). Check onze vergelijking voor details.
Moet ik ABN praten voor beste resultaten?
Nee! Je kunt gewoon je natuurlijke dialect spreken. TalkMark is specifiek getraind op dialecten. Wel helpt duidelijke articulatie, maar overdreven ABN praten is niet nodig en voelt onnatuurlijk.
Waarom werken internationale tools zo slecht voor dialecten?
Internationale tools zoals Otter.ai en Whisper zijn vooral getraind op Engels en Standaardnederlands. Ze hebben minimale training data voor Nederlandse dialecten, wat resulteert in 60-76% nauwkeurigheid versus TalkMark's 90-94%.
Kan AI verschillende dialecten in één gesprek herkennen?
Ja! Als spreker 1 Brabants praat en spreker 2 Limburgs, kan TalkMark beide herkennen. Met sprekerherkenning weet je ook wie welk dialect praat. Dit komt in Q1 2026 als automatische feature.
Hoe verbetert TalkMark zijn dialectherkenning?
We verzamelen (met toestemming) audio-samples van gebruikers, trainen nieuwe modellen, en testen met regionale focus groepen. Community feedback is cruciaal - dus rapporteer fouten via de app!
Hoe werkt dialect-herkenning technisch?
Moderne AI gebruikt deep learning voor spraakherkenning.
Wat maakt dialectherkenning moeilijk?
**1. Fonologische verschillen** Standaardnederlands vs dialecten: | Standaardnederlands | Brabants | Limburgs | |---------------------|----------|-----------| | Goede middag | Goeie middag | Goeije middag | | Ik ga naar huis | Ik ga nao huis | Ich goan nao huus | | Wat zeg je? | Wazegde? | Wat za...
Wat gaat er mis bij internationale tools?
**Voorbeeld Brabants fragment:** > "Ge moet es kome kijke bij ons thuis, da's echt gezellig." **Otter.ai transcribeert:** > "You mode is come key K by once Tuesday us get yourself." **Google Speech-to-Text transcribeert:** > "U moet es komen kijken bij ons thuis, das echt gezellig." (beter, maar ...
Waarom Nederlandse dialecten AI uitdagen
Nederlands lijkt simpel. Tot je van Groningen naar Limburg reist.
Waarom Nederlandse training belangrijk is
De Nederlandse markt wordt vaak verwaarloosd door internationale tech-bedrijven.